4 Meer dan één variabele visualiseren
Dit hoofdstuk focust op het plotten van meer dan één variabele. Eerst spelen we een beetje vals en bekijken we hoe je een tweede variabele kan toevoegen aan een boxplot en aan een staafdiagram. Vervolgens focussen we ons op twee grafiektypes die meer dan één variabele als input hebben: een puntenwolk en een lijngrafiek.
4.1 Boxplot van meerdere groepen
In hoofdstuk 2 maakte je een boxplot van de variabele flipper_length_mm. Stel dat je de verdeling van deze variabele wil plotten naar pinguïnsoort (species). Je zou dit kunnen doen via een boxplot per pinguïnsoort. Er zijn twee manieren om dit aan te pakken: met facets of door een extra scale toe te voegen.
4.1.1 Boxplot met facet_wrap
De code hieronder zou je bekend moeten voorkomen. Je kwam deze reeds tegen in hoofdstuk 2 toen we een boxplot maakte van de variabele flipper_length_mm en daar ook de datapunten zelf aan toevoegden. De enige code die is toegevoegd, vind je op lijn 22. De functie facet_wrap() gebruik je om small multiples te creëren (ook facets genoemd). De facets worden gecreëerd op basis van de variabele die na ~ komt (in dit geval dus species). Via het argument nrow geef je over hoeveel rijen de facets moeten worden geplot.
Laat de code hieronder lopen en bekijk het resultaat. Verander het getal achter nrow vervolgens naar 1 en vergelijk met het vorige resultaat. Merk ook op dat de boxplot van de Adélie-pinguïns nu wel twee outliers bevat (rood ingekleurd). Doordat de datapunten geplot zijn met wat ruis (via geom_jitter()) lijkt het alsof er nog andere datapunten ook outliers zijn. Dit is verwarrend voor de kijker. Door het argument outliers = TRUE in de functie geom_boxplot() op FALSE te zetten vermijd je dat de outliers worden ingekleurd.
4.1.2 Boxplot inkleuren volgens species
Een tweede manier om de verdeling van flipper_length_mm volgens pinguïnsoort zichtbaar te maken, is gebruik maken van kleur. Dit bereik je door aan de functie ggplot() een y-variabele (species) en fill- en color-aesthetic toe te voegen. In de functie geom_jitter() is de oorspronkelijke y-aesthetic (y = 0) weggehaald. In hoofdstuk 3 leerde je zelf bepalen welke kleuren ggplot2 moet gebruiken bij het inkleuren naar pinguïnsoort (zie Section 3.2.5). Voeg deze code hier toe en kies zelf drie kleuren.
4.1.3 Boxplot inkleuren met ingebouwde kleurpaletten
Tot nu toe bepaalde je zelf de kleuren voor het inkleuren volgens pinguïnsoort. Er zitten echter verschillende kleurpaletten ingebouwd in ggplot2. In dit OLP focussen we ons op de kleurpaletten van RColorBrewer.
Om een kleurenpalet van RColorBrewer te gebruiken, hanteer je de functie scale_fill_brewer() en/of scale_color_brewer(). Tussen de haakjes voeg je het type schaal toe (kwalitatief "qual", sequentieel "seq" of divergerend "div") en de naam van het palet dat je wenst te gebruiken. Bijvoorbeeld, scale_fill_brewer(type = "qual", palette = "Set2). Hieronder vind je de verschillende paletten beschikbaar in RColorBrewer per type kleurschaal (en de namen van de kleurenpaletten). Je vindt meteen ook de code terug om deze paletten te bekijken in RStudio. Door aan de functie display.brewer.all() nog het argument colorblindFriendly toe te voegen, krijg je alleen paletten te zien die geschikt zijn voor mensen met kleurenblindheid.
Klik hier voor code
RColorBrewer::display.brewer.all()
Voeg nu zelf een gepast kleurenpalet uit RColorBrewer toe aan de plot. (Je wil zowel de opvulling als de omtrek van de boxplots inkleuren!) Denk daarbij goed na over het type variabele dat species is. Dit bepaalt immers welk type kleurenpalet je dient te gebruiken.
4.2 Staafdiagram met meerdere categorische variabelen
Hoofdstuk 3 focuste op het maken van een staafdiagram van het aantal pinguïns per soort. We hielden daarbij geen rekening met het geslacht van de pinguïns. Hier gaan we dat wel doen door een tweede categorische variabele (sex) toe te voegen aan het staafdiagram.
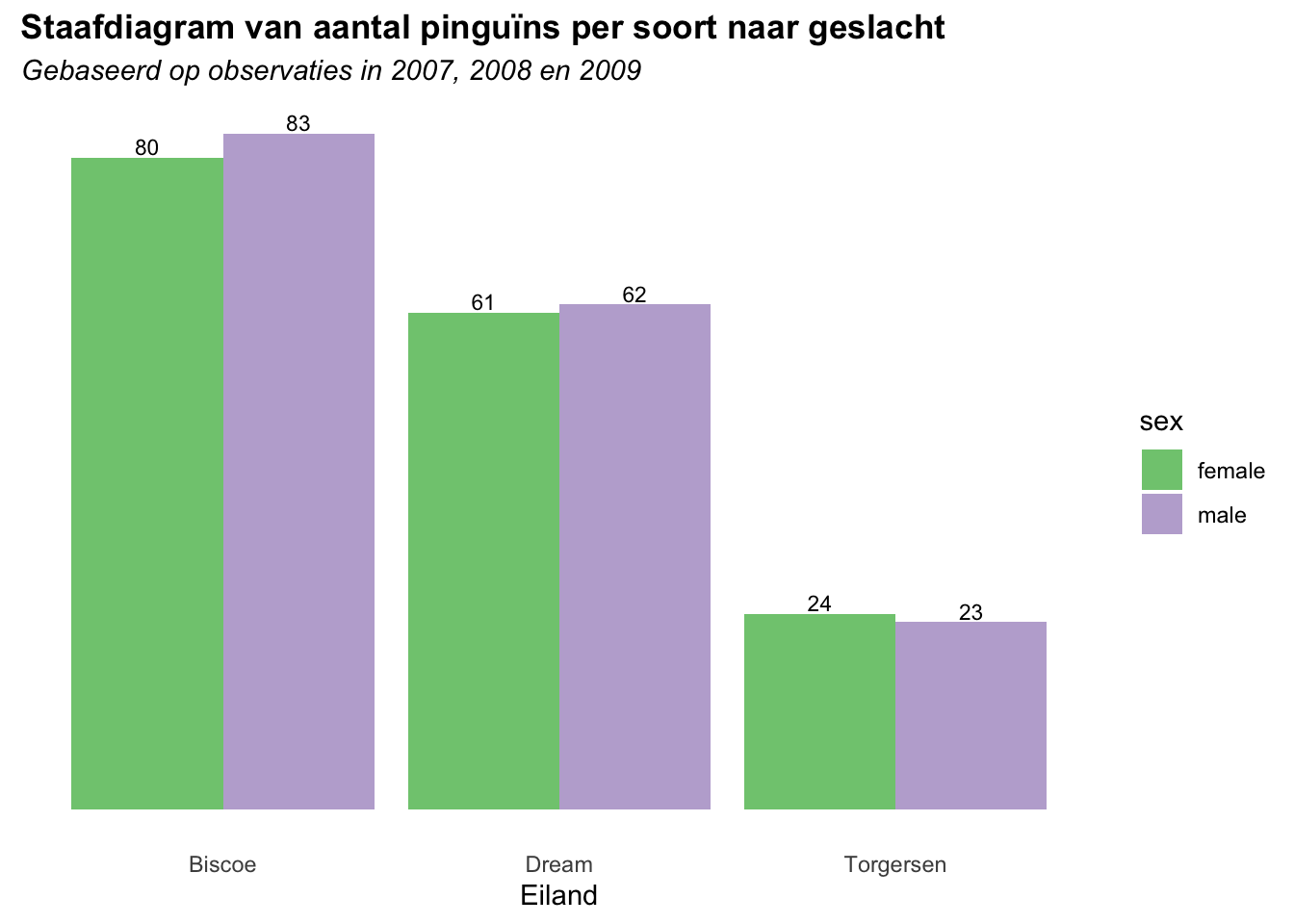
4.2.1 Staafdiagram met geom_bar()
Om een staafdiagram te maken van de variabelen sex en species, gebruik je de functie geom_bar(). Hierbij dien je twee aesthetics te specificeren: een x-variabele (sex) en een fill-variabele (species). Verder geef je via het argument position aan hoe de staven (die beide geslachten weergeven) gepositioneerd moeten worden. Je kan daarbij kiezen uit position = position_stack() (staven die geslacht weergeven staan op elkaar) of position = position_stack() (staven staan naast elkaar). Verander in de code hieronder de waarde voor het argument position en kijk wat er gebeurt.
4.2.2 Staafdiagram met relatieve frequenties
Tot nu toe bevatte het staafdiagram telkens de absolute aantallen. Als je een staafdiagram met relatieve frequenties wil, dan kies je voor position = position_fill()`. Probeer dit hieronder uit!
Je merkte vermoedelijk al op dat het geslacht van enkele pinguïns niet werd geregistreerd. Deze worden door geom_bar() nu als een derde categorie beschouwd. Er zijn verschillende manieren om dit te voorkomen. De simpelste manier is toegevoegd aan de code hieronder en maakt gebruik van de functie filter() uit het package dplyr.
4.2.3 De staven labelen
We werken verder met het staafdiagram met de absolute frequenties. Je kan de aantallen die de staven weergeven ook labelen door geom_text() toe te voegen aan de code. Je dient daarbij aan te geven welk label (het juiste aantal) boven elke staaf geplaatst moet worden. Dat doe je door aes(label = after_stat(count) toe te voegen aan geom_text(). Verder dien je ook in geom_text() expliciet de positie van de staven aan te geven (position = position_dodge(width = 0.90)) Het argument width = 0.9 wordt gebruikt om de plaats van de labels te bepalen. Speel met de waarde van dit argument en kijk wat er gebeurt.
Kan je de code aanpassen zodanig dat de staven op elkaar geplaatst worden? Je zal daarbij ook met de waarde van het argument vjust moeten spelen om de labels op een ‘goede’ positie te krijgen.
4.2.4 Inkleuren volgens geslacht
In een laatste stap voeg je een gepast kleurenpalet uit RColorBrewer toe aan de plot om de variabele sex in te kleuren.
4.3 Puntenwolk
Tot nu toe hebben we telkens maar een x- of een y-variabele meegegeven als aesthetic. Daar komt nu verandering in bij het maken van een puntenwolk die het verband tussen lichaamsgewicht (body_mass_g) en vleugellengte (flipper_length_mm) weergeeft.
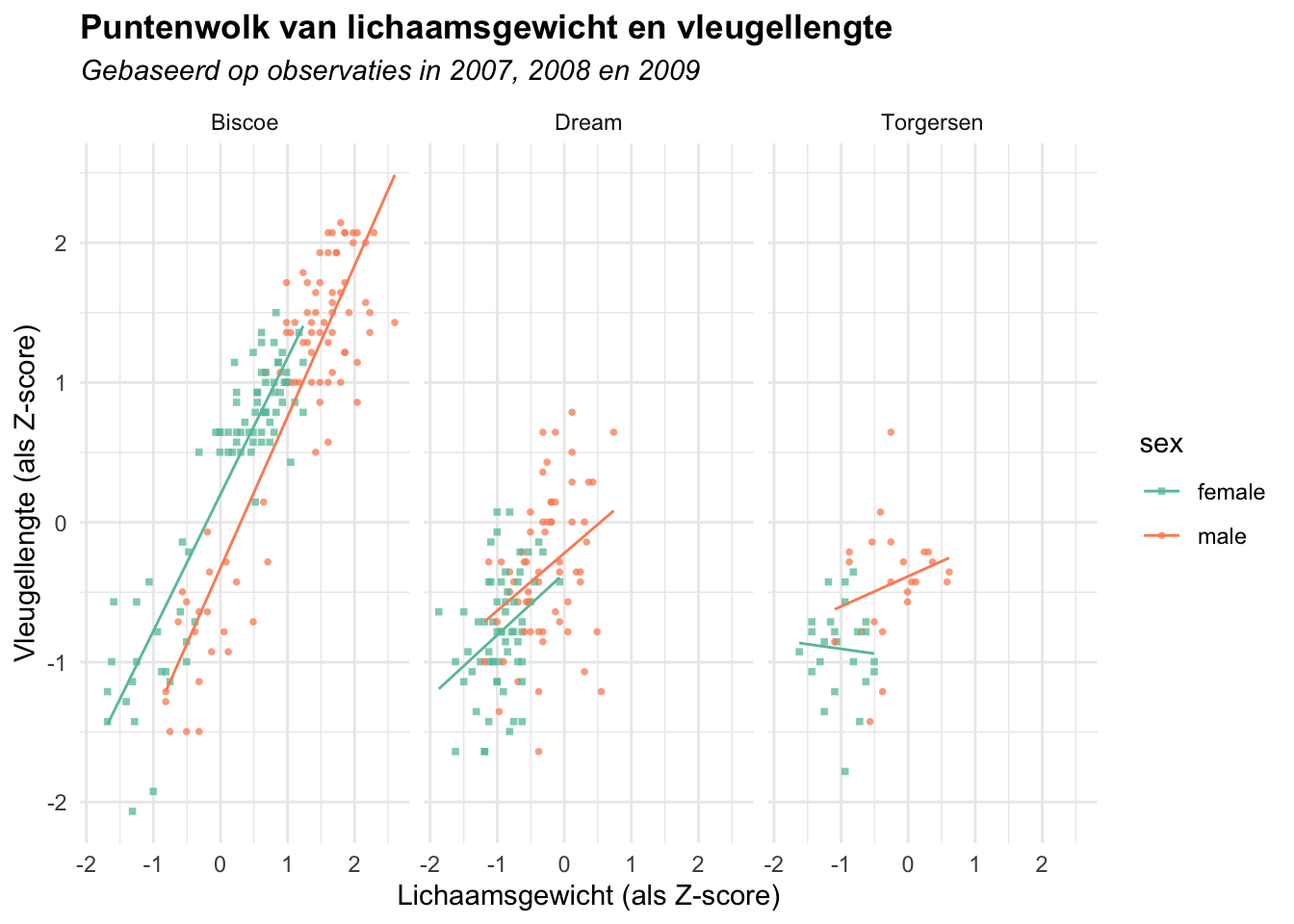
4.3.1 Puntenwolk met geom_point()
Om een puntenwolk te maken, gebruik je de functie geom_point(). Je dient daarbij aan te geven welke variabele op de x-as dient te komen en welke variabele op de y-as.
Kopieer de code hieronder naar RStudio op je eigen laptop en probeer deze uit. Zorg dat de packages tidyverse en palmerpenguins geladen zijn. Door hieronder op ‘Plot’ te klikken, vind je het verwachte resultaat terug.
Klik hier voor code
ggplot(
data = penguins,
aes(
x = body_mass_g,
y = flipper_length_mm
)
) +
geom_point(
shape = 16,
size = 1,
color = "#AAAA17",
alpha = 0.75
) +
labs(
title = "Puntenwolk van lichaamsgewicht en vleugellengte",
subtitle = "Gebaseerd op observaties in 2007, 2008 en 2009",
x = "Lichaamsgewicht (in g)",
y = "Vleugellengte (in mm)"
) +
theme_minimal() +
theme(
plot.title = element_text(face = "bold"),
plot.subtitle = element_text(face = "italic")
)Warning: Removed 2 rows containing missing values or values outside the scale range
(`geom_point()`).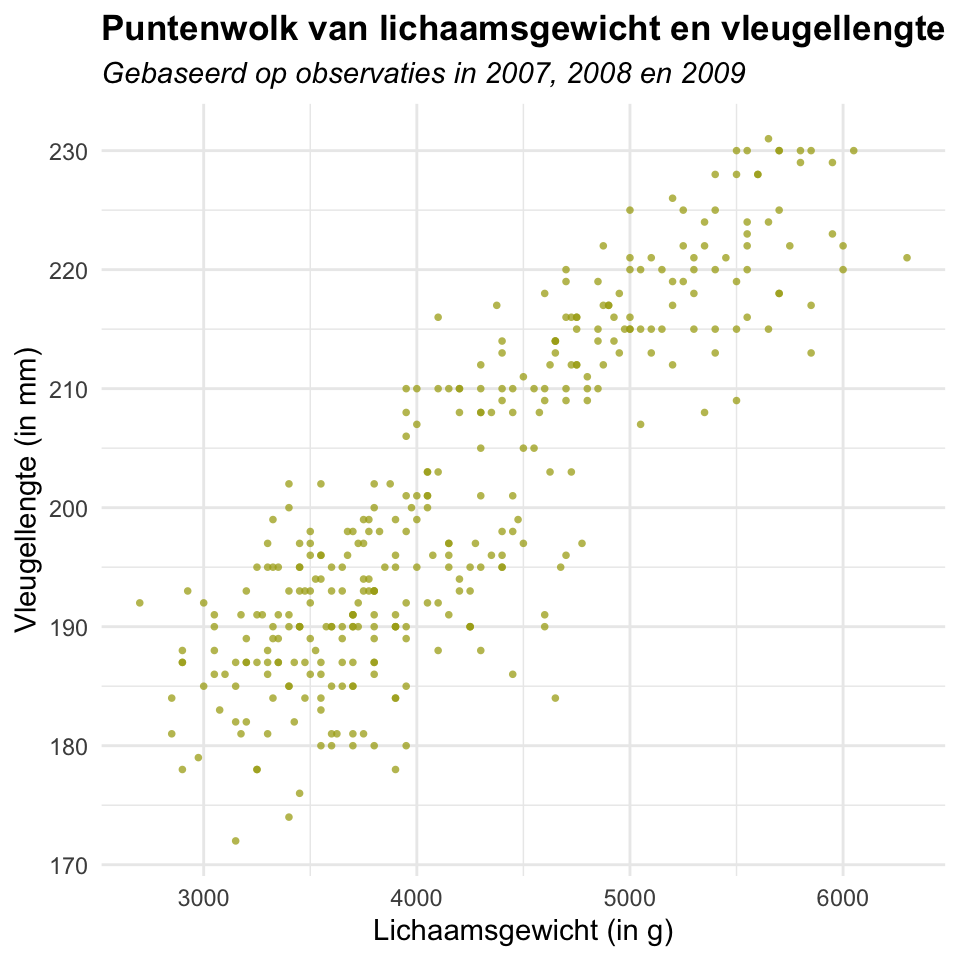
Merk op dat in geom_point() de kleur van de datapunten wordt gespecificeerd met behulp van een hexadecimal (HEX). Dit is een andere manier om kleuren te specificeren. Via deze link vind je informatie terug over de verschillende manieren waarop je in R kleuren kan benoemen.
4.3.2 Een trendlijn toevoegen met geom_smooth()
Vaak wil je het verband tussen body_mass_g en flipper_length_mm ook weergeven met een trendlijn. Je kan eenvoudig een trendlijn aan je puntenwolk toevoegen met behulp van de functie geom_smooth(). Deze functie vraagt als input om een x- en een y-variabele. In de code hieronder worden deze echter niet meegegeven. geom_smooth() ‘erft’ dan de x- en y-variabelen die in de functie ggplot() zijn meegegeven. Verder vind je vier argumenten terug:
method = "lm": dit argument geeft aan welke methodegeom_smooth()moet gebruiken bij het plotten van de trendlijn ("lm"staat voor een lineaire trendlijn)
se: bepaalt of de onzekerheid rond de trendlijn wordt weergegeven (se = TRUE) of niet (se = FALSE).
linewidth: bepaalt de dikte van de lijn
color: bepaalt de kleur van de lijn
Speel in de code hieronder met de argumenten se, linewidth en color en bekijk wat het effect is.
4.3.3 Vorm van datapunten volgens geslacht
Stel dat je ook wil visualiseren wat het geslacht van de pinguïns is. Je zou daarvoor kleur kunnen toevoegen aan de puntenwolk, maar er zijn ook andere mogelijkheden. Eén daarvan is de vorm van de punten laten afhangen van de variabele sex. Hiertoe is er in de code hieronder een extra aesthetic toegevoegd aan de geom_point()-functie: shape = sex. Verder is ook de functie scale_shape_manual() toegevoegd met het argument values = c(15, 16). Op die manier kan je zelf aangeven welke vormen moeten worden gebruikt om de mannetjes- en vrouwtjespinguïns weer te geven.
Klik hier voor code
penguins %>%
filter(!is.na(sex)) %>%
ggplot(
aes(
x = body_mass_g,
y = flipper_length_mm
)
) +
geom_point(
aes(shape = sex),
size = 1,
color = "#AAAA17",
alpha = 0.75
) +
geom_smooth(
method = "lm",
se = FALSE,
linewidth = 0.5,
color = "black"
) +
scale_shape_manual(
values = c(15, 16)
) +
labs(
title = "Puntenwolk van lichaamsgewicht en vleugellengte",
subtitle = "Gebaseerd op observaties in 2007, 2008 en 2009",
x = "Lichaamsgewicht (in g)",
y = "Vleugellengte (in mm)"
) +
theme_minimal() +
theme(
plot.title = element_text(face = "bold"),
plot.subtitle = element_text(face = "italic")
)`geom_smooth()` using formula = 'y ~ x'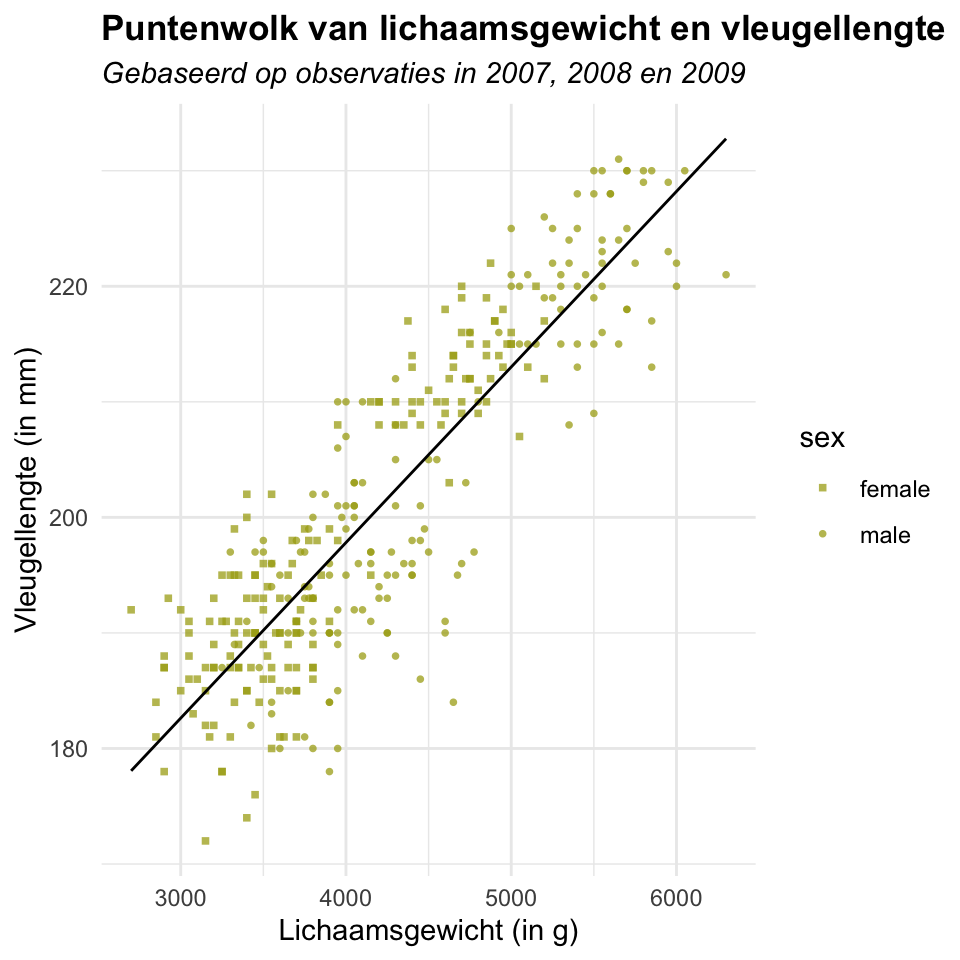
Had je ook een tweede trendlijn verwacht? Door de aesthetic shape = sex toe te voegen aan geom_point() wordt deze alleen toegepast op deze geom. Om ook een trendlijn te plotten per geslacht zijn er twee opties:
shape = sexook als aesthetic toevoegen aangeom_smooth()
shape = sextoevoegen als aesthetic aanggplot()zodat het wordt toegepast op alle geoms die volgen.
Kies één van beide opties en pas de code hieronder aan. Lukt het je om een trendlijn per geslacht te plotten?
4.3.4 Kleur toevoegen aan de scatterplot
De vorm van de punten is nu aangepast aan het geslacht van de pinguïns. Zorg er nu ook voor dat de kleur van de datapunten en de trendlijnen afhangen van de variabele sex. Voeg daarvoor hieronder de nodige code toe. Gebruik meteen ook een gepast RColorBrewer-palet.
4.3.5 Puntenwolk met facet_wrap()
Om de puntenwolk ‘af’ te maken, voeg je aan je code nog de functie facet_wrap(~island) toe. Dit zorgt ervoor dat er drie puntenwolken worden geplot (één per eiland waar er pinguïns wonen). Als je de code hieronder laat lopen, zal je merken dat de breaks op de x-as en y-assen in alle facets precies hetzelfde zijn. Je kan dit aanpassen door het argument scales = "free" toe te voegen aan de functie facet_wrap(). Dit argument kan ook de waarde "free_x" of "free_y" aannemen. Probeer de verschillende waardes uit en kijk wat hun effect is.
4.3.6 Puntenwolk van gestandaardiseerde variabelen
Stel dat je dezelfde puntenwolk wil maken, maar nu met gestandaardiseerde variabelen op de x- en y-as. Dit kan heel eenvoudig door gebruik te maken van de functie mutate() uit het package dplyr. Tussen de haakjes van de functie geef je aan welke variabele(n) je wenst aan te maken. Hier zijn dat de variabelen body_mass_Z en flipper_length_Z. Deze variabelen zijn gestandaardiseerd door gebruik te maken van de functie scale (body_mass_Z) en door zelf de nodige berekeningen uit te voeren (flipper_length_Z). Het enige wat je verder dient te doen, is de namen van de x- en y- variabele in de aesthetics van de ggplot()-functie aanpassen (en de labels van de x- en y-as). Doe dit en laat de code lopen!
4.4 Lijngrafiek
In hoofdstuk 3 maakten we staafdiagrammen van het aantal pinguïns per soort. Hier gaan we na hoeveel pinguïns per soort er werden geteld in de drie opeenvolgende jaren waarin de observaties plaatsvonden. Om dit weer te geven, maken we gebruik van een lijngrafiek
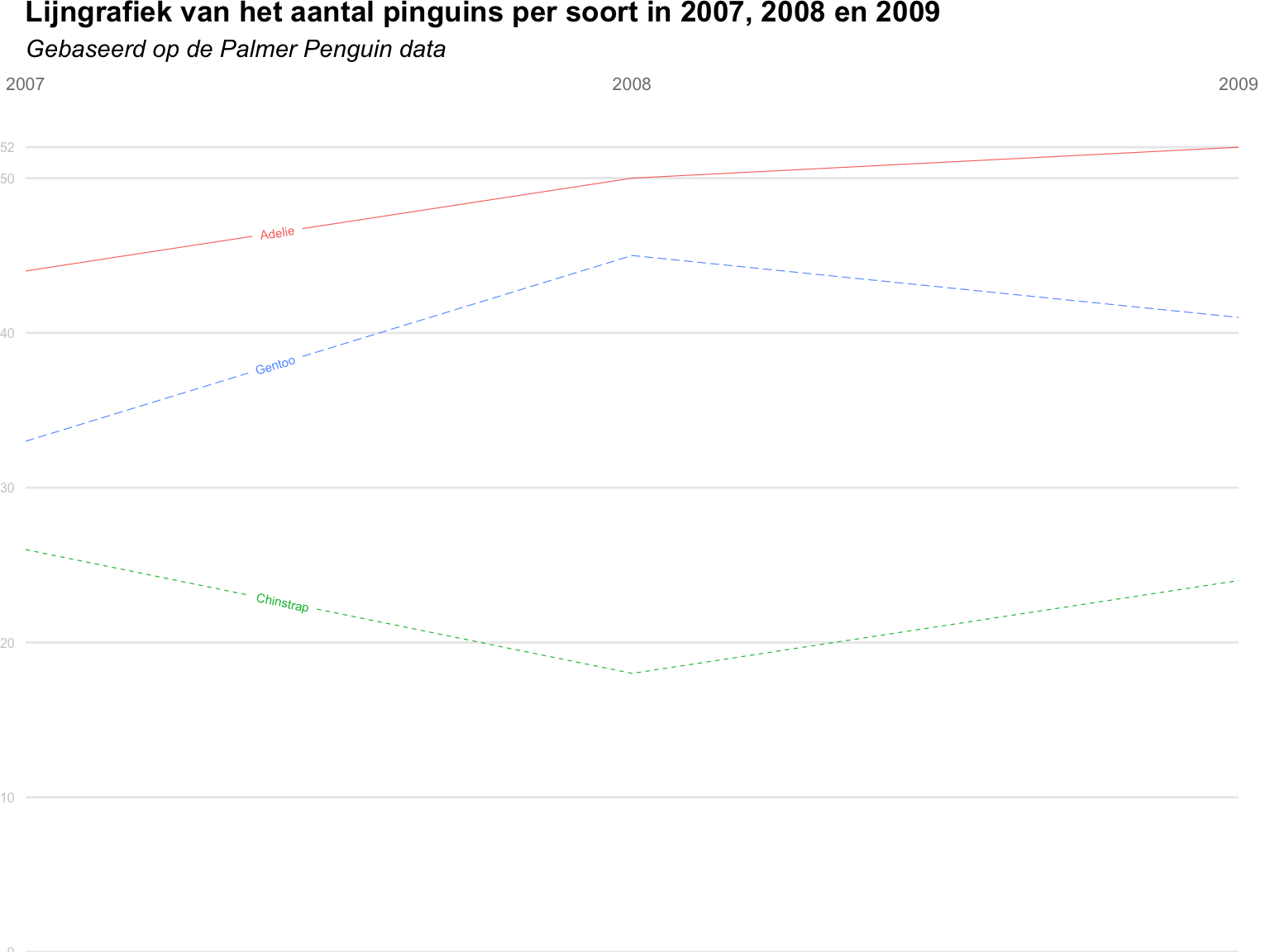
4.4.1 Lijngrafiek met geom_line()
Vooraleer je een lijngrafiek kan maken van pinguïnsoort naar jaar dien je een nieuwe dataset aan te maken die de frequenties per pinguïnsoort per jaar bevat. Hiervoor kan je gebruik maken van een combinatie van de functies group_by() en count(). Laat de code hieronder lopen en bekijk het resultaat.
Je creëerde een dataset (een tibble in tidyverse-taal) gemaakt die je kan gebruiken om een lijngrafiek te maken. Daarvoor maak je gebruik van het geom geom_line() waarbij je year als x-variabele meegeeft en n als y-variabele. Het derde aesthetic dat je aan ggplot() toevoegt is group = species. Test hieronder uit wat er gebeurt met de lijngrafiek als je group weglaat.
4.4.2 Basisargumenten geom_line()
Je kan verschillende argumenten toevoegen aan de functie geom_line(). De betekenis van color (kleur van de lijn) en van alpha (transparantie van de lijn) ken je al. Met de argumenten linewidth en linetype pas je respectievelijk de dikte en de stijl van de lijn aan. Qua lijntype kan je kiezen uit de volgende waarden:
- “solid” of 1
- “dashed” of 2
- “dotted” of 3
- “dotdash” of 4.
- “longdash” of 5
- “twodash” of 6
- “blank” of 0
Speel in de code hieronder met de argumenten linewidth en linetype en bekijk wat het effect is.
4.4.3 Breaks op x- en y-as aanpassen
De breaks op de x- en de y-as dienen nog aangepast te worden. Voeg daarvoor in de code hieronder de nodige argumenten toe aan de functies scale_x_continuous() en scale_y_continuous(). Hieronder wordt per as aangegeven voor welke zaken je argumenten dient toe te voegen.
Zorg ervoor dat de x-as:
- alleen de breaks 2007, 2008 en 2009 bevat,
- van 2007 t.e.m. 2009 loopt,
- bovenaan wordt weergegeven en - geen titel (naam) meer heeft.
Zorg ervoor dat de y-as:
- de volgende breaks bevat: 10, 20, 30, 40, 50, 52,
- van 0 t.e.m. 55 loopt,
- geen titel (naam) meer heeft.
Merk op dat er nog twee argumenten zijn toegevoegd aan de functie theme(): axis.text.x = element_text(size = 8, color = "grey50") en axis.text.y = element_text(size = 6, color = "grey80"). Deze argumenten definiëren de kleur en grootte van de labels op de x- en y-as.
4.4.4 Lijntype en lijnkleur volgens pinguïnsoort
Tot nu toe is elke lijn van hetzelfde type en dezelfde kleur. Door aan ggplot() het aesthetic linetype = species toe te voegen, wordt het lijntype afhankelijk van de pinguïnsoort. Als je zelf wil bepalen welke lijntypes hiervoor worden gebruikt, dan voeg je ook scale_linetype_manual(values = c(1, 2, 3)) toe. Voeg deze zaken toe aan de code hieronder.
Zorg er ook voor dat de kleur van de lijnen ook afhangt van de variabele species. Voeg daarvoor hieronder de nodige code toe. Gebruik meteen ook een gepast RColorBrewer-palet.
Aan de theme()-functie zijn bijkomende argumenten toegevoegd om alle ’minor’gridlijnen te verwijderen (panel.grid.minor = element_blank()), de ’major’gridlijnen die vertrekken vanuit de x-as (panel.grid.major.x = element_blank()) en de legende naar onderen te verplaatsen (legend.position = "bottom").
4.4.5 Lijnen zelf labellen
Als je de legende uit een plot kan weglaten, is dat meestal een goed idee. Daardoor moet de kijker geen informatie vanop twee plaatsen (de legende en de lijn)combineren. Een handig alternatief voor een legende is in dit geval het rechtstreeks labelen van de verschillende lijnen. Dit kan je eenvoudig doen met behulp van het package geomtextpath.
Het pakket geomtextpath bevat voor enkele geoms een aangepaste versie die toelaat om lijnen (functie geom_textline()) of trendlijnen (functie geom_textsmooth()) te labelen. Het gebruik van deze functies is hetzelfde als dat van de originele geoms, met als enige toevoeging het aesthetic label. In de code hieronder is pinguïnsoort (species) als label meegegeven. Doordat je in de ggplot()-functie hebt aangegeven dat de lijnen moeten worden ingekleurd volgens species wordt dit aan geom_textline() doorgegeven. De tekst in geom_textline() wordt dus ook volgens pinguïnsoort ingekleurd. (Dit geldt ook voor het lijntype.). De argumenten size=2, linewidth = 0.2 en hjust = 0.2 bepalen respectievelijk de grootte van de letters, de dikte van de lijn en de locatie van de labels op de lijnen.
Kopieer de code hieronder naar RStudio op je eigen laptop en probeer deze uit. Zorg dat de packages tidyverse, palmerpenguins en geomtextpath geladen zijn. (Vergeet geomtextpath niet eerst te installeren.) Door hieronder op ‘Plot’ te klikken, vind je het verwachte resultaat terug.
Klik hier voor code
library(geomtextpath)
penguins %>%
filter(!is.na(sex)) %>%
group_by(year, species) %>%
count() %>%
ggplot(
aes(
x = year,
y = n,
group = species,
color = species,
linetype = species
)
) +
geom_textline(
aes(label = species),
size = 2,
linewidth = 0.2,
hjust = 0.2
) +
labs(
title = "Lijngrafiek van het aantal pinguins per soort in 2007, 2008 en 2009",
subtitle = "Gebaseerd op de Palmer Penguin data",
) +
scale_x_continuous(
breaks = c(2007, 2008, 2009),
limits = c(2007, 2009),
name = NULL,
position = "top"
) +
scale_y_continuous(
breaks = c(seq(0, 50, 10), 52),
limits = c(0, 55),
name = NULL
)+
scale_fill_brewer(
type = "qual", palette = "Set1"
) +
coord_cartesian(expand = FALSE) +
theme_minimal() +
theme(
plot.title = element_text(face = "bold"),
plot.subtitle = element_text(face = "italic"),
plot.margin = margin(0,5,0,0, unit = "mm"),
axis.text.x = element_text(size = 8, color = "grey50"),
axis.text.y = element_text(size = 6, color = "grey80"),
panel.grid.major.x = element_blank(),
panel.grid.minor = element_blank(),
legend.position = "none"
)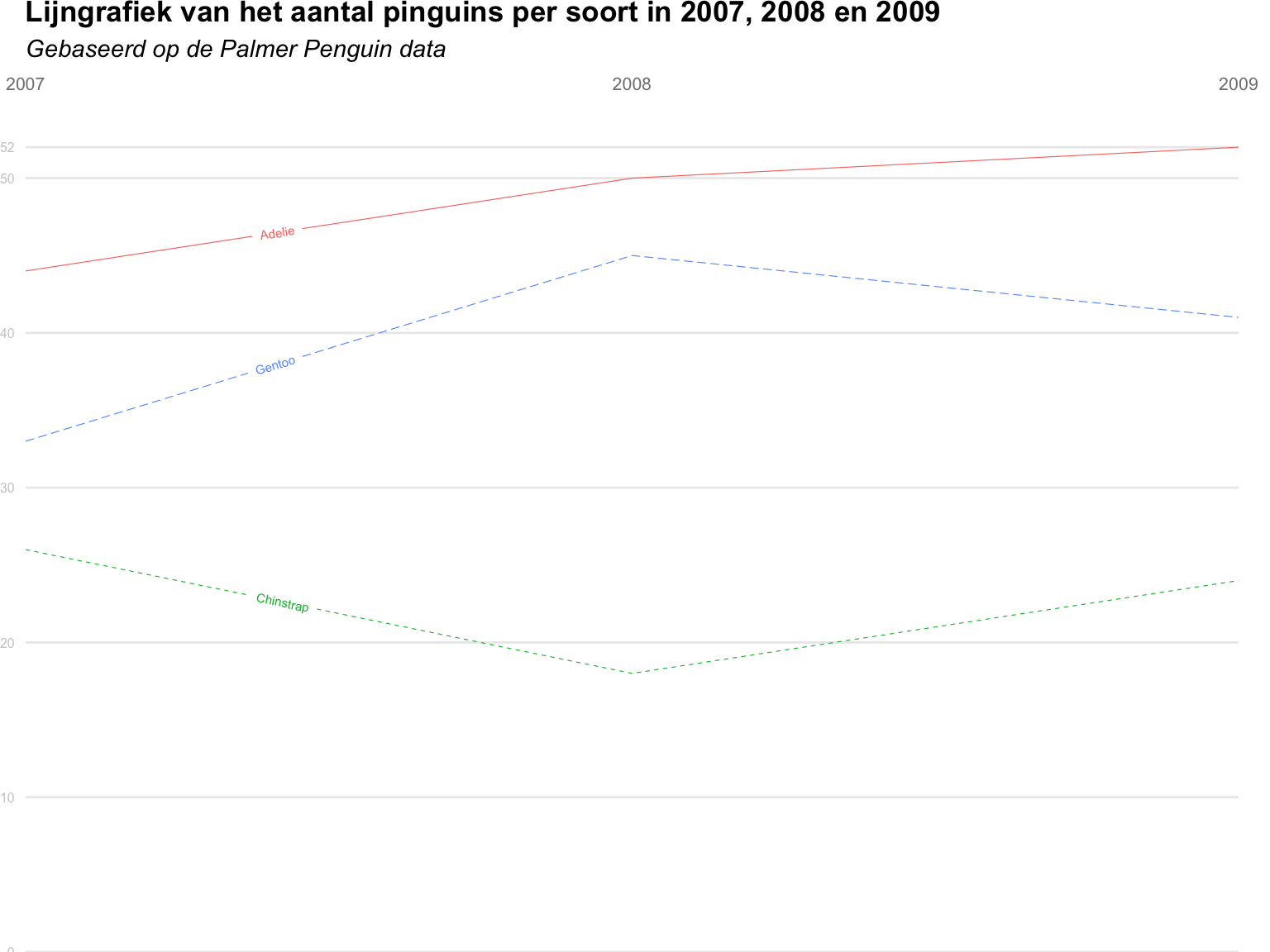
De legende is verwijderd door in theme() het argument legend.position als waarde "none" mee te geven. De functie coord_cartesian(expand = FALSE) zorgt ervoor dat de overtollige ‘plaats’ aan de linker- en rechterkant van de grafiek wordt verwijderd.
4.5 Een univeRsum aan visualisatiemogelijkheden
In dit OLP komen slechts een beperkt aantal grafiektypes aan bod. Via ggplot2 kan je echter (bijna) elke denkbare grafiek maken. Handige vertrekpunten om verder aan de slag te gaan met ggplot2 zijn de cheat sheet ‘datavisualisatie met ggplot2’ en de website from Data to Viz. Deze website bevat niet alleen een handige tool om gepaste grafieken te kiezen voor het type data te je hebt, het geeft er ook de nodige R-code bij! Tenslotte is het ook goed om mee te geven dat er al een hele hoop packages zijn ontwikkeld die verderbouwen op ggplot2. Een overzicht van al deze extensies vind je op deze website.
4.6 Overzicht van functies en argumenten uit hoofdstuk 4
De onderstaande functies en argumenten zijn in dit hoofdstuk aan bod gekomen:
functie
geom_boxplot()met aestheticsxofyen de argumentenoutliers,outlier.fill,fill,colorenalphafunctie
geom_jitter()met aestheticsxenyen de argumentenheight,size,shapeenalpha
functie
geom_bar()met de argumentenposition
functie
geom_text()met de argumentenlabel,position,vjust,statencolor
functie
geom_line()met de argumentenlinewidth,linetypeencolor
functie
geom_textline()met de argumentenlabel,size,linewidthencolorfuncties
scale_color_brewer()enscale_fill_brewer()met de argumententypeenpalette
functie
scale_shape_manual()met het argumentvalues
functie
scale_linetype_manual()met het argumentvalues
functie
facet_wrap()met de argumenten~variableennrow
functies
position_dodge()(met argumentwidth),position_stack()enposition_fill()
functie
filter()
functie
mutate()
Let op! De meeste functies beschikken over veel meer argumenten dan deze die in dit hoofdstuk aan bod zijn gekomen. Om hier een overzicht van te krijgen, kan je de help-functie gebruiken. Ook de specifieke aesthetics die je kan toevoegen aan elke *geom*-functie zijn uitgebreider dan je hier terug vindt. Daarover meer in de volgende hoofdstukken.